The goal of this report is to predict housing prices in California from property features. To this end, we use the california-housing-dataset from scikit-learn.
from sklearn.datasets import fetch_california_housingcalifornia = fetch_california_housing(as_frame=True)print(california.DESCR)
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block group
- HouseAge median house age in block group
- AveRooms average number of rooms per household
- AveBedrms average number of bedrooms per household
- Population block group population
- AveOccup average number of household members
- Latitude block group latitude
- Longitude block group longitude
:Missing Attribute Values: None
This dataset was obtained from the StatLib repository.
https://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.html
The target variable is the median house value for California districts,
expressed in hundreds of thousands of dollars ($100,000).
This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).
A household is a group of people residing within a home. Since the average
number of rooms and bedrooms in this dataset are provided per household, these
columns may take surprisingly large values for block groups with few households
and many empty houses, such as vacation resorts.
It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function.
.. rubric:: References
- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297
from IPython.display import displayimport pandas as pddf = california.frameseparator = pd.DataFrame([['...'] *len(df.columns)], columns=df.columns, index=['...'])display(pd.concat([df.head(), separator, df.tail()]))# df.head()
MedInc
HouseAge
AveRooms
AveBedrms
Population
AveOccup
Latitude
Longitude
MedHouseVal
0
8.3252
41.0
6.984127
1.02381
322.0
2.555556
37.88
-122.23
4.526
1
8.3014
21.0
6.238137
0.97188
2401.0
2.109842
37.86
-122.22
3.585
2
7.2574
52.0
8.288136
1.073446
496.0
2.80226
37.85
-122.24
3.521
3
5.6431
52.0
5.817352
1.073059
558.0
2.547945
37.85
-122.25
3.413
4
3.8462
52.0
6.281853
1.081081
565.0
2.181467
37.85
-122.25
3.422
...
...
...
...
...
...
...
...
...
...
20635
1.5603
25.0
5.045455
1.133333
845.0
2.560606
39.48
-121.09
0.781
20636
2.5568
18.0
6.114035
1.315789
356.0
3.122807
39.49
-121.21
0.771
20637
1.7
17.0
5.205543
1.120092
1007.0
2.325635
39.43
-121.22
0.923
20638
1.8672
18.0
5.329513
1.17192
741.0
2.123209
39.43
-121.32
0.847
20639
2.3886
16.0
5.254717
1.162264
1387.0
2.616981
39.37
-121.24
0.894
Data exploration
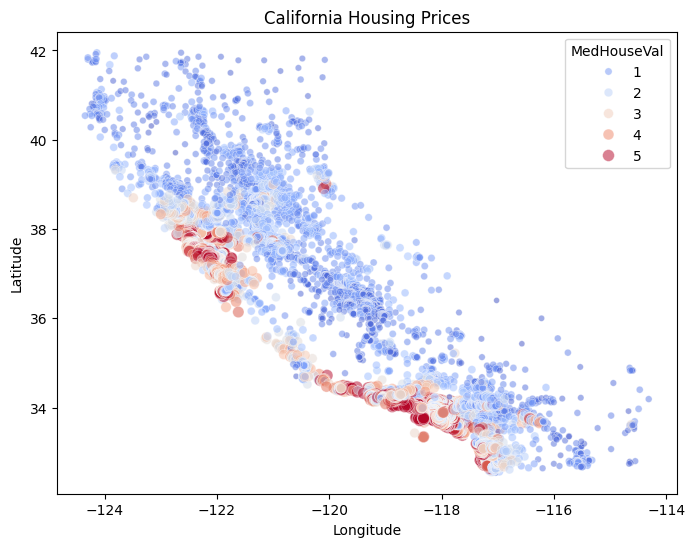
Below, we show the geographic distribution of house prices in California. In the scatter plot, each point represents a location colored and sized by its median house price.
import seaborn as snsimport matplotlib.pyplot as pltplt.figure(figsize=(8, 6))sns.scatterplot( data=df, x='Longitude', y='Latitude', hue='MedHouseVal', size='MedHouseVal', palette='coolwarm', alpha=0.5,)plt.legend(title='MedHouseVal', loc='best')plt.title('California Housing Prices')plt.show()
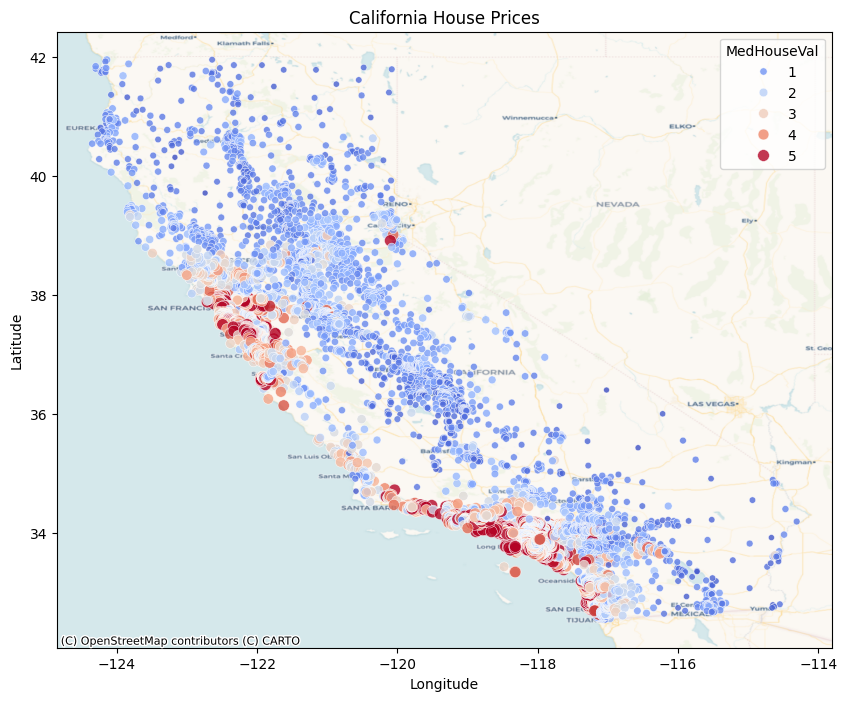
To visualize geographic trends in California housing price (e.g. higher prices near coastal areas and urban centers, and lower prices inland), we overlay prices with the California map.
import contextily as ctxplt.figure(figsize=(10, 8))ax = plt.gca()sns.scatterplot( data=df, x='Longitude', y='Latitude', hue='MedHouseVal', size='MedHouseVal', palette='coolwarm', alpha=0.8, ax=ax)## other providers# ctx.providers.OpenStreetMap.Mapnik# ctx.providers.CartoDB.Positron# ctx.providers.CartoDB.Voyager# ctx.providers.Esri.WorldImageryctx.add_basemap(ax, crs='EPSG:4326', source=ctx.providers.CartoDB.Voyager)ax.set_xlabel('Longitude')ax.set_ylabel('Latitude')ax.set_title('California House Prices')plt.legend(title='MedHouseVal', loc='best')# plt.tight_layout()plt.show()
Finally, we display results via an interactive map. The heatmap highlights areas with higher median house values, while clusters show the geographic distribution of all properties. In the heatmap, higher prices appear as warmer colors (yellow/red), lower prices as cooler colors (blue/purple) and intermediate prices as green.
import foliumfrom folium.plugins import HeatMap,FastMarkerCluster# center map on Californiam = folium.Map(location=[36.7783, -119.4179], zoom_start=6)# coordinateslocations = df[['Latitude', 'Longitude']].values.tolist()# prepare data for heatmap: [lat, lon, weight]heat_data = [ [row['Latitude'], row['Longitude'], row['MedHouseVal']]for _, row in df.iterrows()]# add heatmap layerHeatMap(heat_data, radius=5, blur=5).add_to(m)# add cluster layer FastMarkerCluster(locations).add_to(m)m
Make this Notebook Trusted to load map: File -> Trust Notebook
Splitting data
We partition data in training (80% of the data) to fit the model and in test set (20% of the data) to evaluate the model.
from sklearn.model_selection import train_test_splitX = california.datay = california.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
Predict housing prices
Feature selection
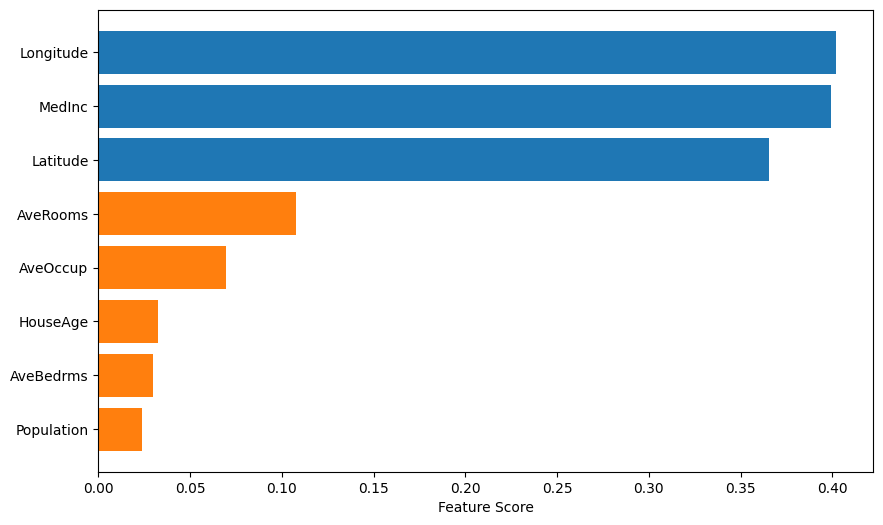
We use mutual information to select the most relevant features for predicting house prices.
To predict California housing prices, we train a simple linear regression model using the three most informative features identified through mutual information: median income, latitude, and longitude. This approach captures linear relationships between geographic location, income levels and housing prices. Model performance is evaluated using cross-validation and validated on a held-out test set (unseen data) to assess its generalization capability.
On average, the model predictions are about $75,000 away from the actual house price (RMSE: $75,163). Since the median price is $179,700, the error is quite high (relative error is about 42%).
The average absolute error (MAE) is about $55,000. This means that half of the predictions are off by less than $55,000, and half by more. MAE is less affected by large outliers than RMSE, providing a more robust measure of typical prediction error.
The model explains about 57% of the variance in house prices (\(R^2\): 0.567). This is a moderate fit: the model captures more than half of the price variation, but there is still substantial unexplained variance.
from sklearn.metrics import root_mean_squared_error, mean_absolute_error, r2_scorermse = root_mean_squared_error(y_test, y_pred)mae = mean_absolute_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print("Model Performance Metrics:")print(f"RMSE: ${rmse*100000:.2f}") # Multiply by 100000 since prices are in this scaleprint(f"MAE: ${mae*100000:.2f}")print(f"R²: {r2:.3f}")
Model Performance Metrics:
RMSE: $75163.22
MAE: $55266.91
R²: 0.567
Conclusions and next step
While this linear model has moderate explanatory power, its prediction error is quite large compared to affordable house prices (for example, the 10th percentile price is $82,300). To improve performance, gradient boosting algorithms (such as XGBoost or LightGBM) could be used instead to capture complex and nonlinear relationships between features. Additionally, hyperparameter tuning using Bayesian methods - such as hyperopt - could further enhance model performance.