classes = ['Nucleus','Cytoplasm','Extracellular','Mitochondrion','Cell membrane','ER','Chloroplast','Golgi apparatus','Lysosome','Vacuole']dico_classes_subcell={i:v for i,v inenumerate(classes)}for i in dico_classes_subcell.keys():print('Target', i, dico_classes_subcell[i])
This CNN uses two convolutional layers with a 3x3 kernel and a ReLU activation, followed by max pooling to downsample the sequence length while preserving the feature dimension. The resulting features are flattened and fed into a fully connected layer, which maps the extracted features to the 10 subcellular localizations.
class ProteinLoc_CNN(nn.Module):def__init__(self, seq_len=400, n_feat=20, n_class=10, out_channels=10):super().__init__()## - two 2D (data are 2D (400 x 20)) convolutional layers with:## - a 3x3 kernel to capture local features## - a 1x1 padding to preserve spatial dimension (output feature map dimension = input feature map dimension)## - a max pooling with a 5x1 padding to reduce the sequence length by a factor of 5 preserving feature dimensionself.conv = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=out_channels, kernel_size=(3, 3), padding=(1, 1)), nn.ReLU(), nn.MaxPool2d(kernel_size=(5, 1), stride=(5, 1)), nn.Conv2d(in_channels=out_channels, out_channels=out_channels*2, kernel_size=(3, 3), padding=(1, 1)), nn.ReLU(), nn.MaxPool2d(kernel_size=(5, 1), stride=(5, 1)) )## flatten the layer to transforms the 2D feature maps from the convolutional layers into a 1D vectorself.flatten = nn.Flatten()## fully connected layer## map the features from the convolutional layers to the subcellular localizationsself.dense_layers = nn.Sequential( nn.Linear(out_channels *2* (seq_len // (5*5)) * n_feat, n_class) )def forward(self, x):## add a channel to reshape the data in the form (batch_size, 1, 400, 20) and## make them compatible with the Conv2d shape (batch_size, channels, height, width) x = x.unsqueeze(1) x =self.conv(x) x =self.flatten(x) x =self.dense_layers(x)return x# initialize the modelmodel = ProteinLoc_CNN(seq_len=400, n_feat=20, n_class=10, out_channels=40).to(device)print(model)# check modelx, _ = train_dataset[0]print(pms.summary(model, x.reshape(1, 400, 20).to(device), show_input=False))
class ProteinLoc_FNN(torch.nn.Module):def__init__(self , input_dim =8000, hidden_dim = [80], output_dim =10, dropout_fraction =0.25):super().__init__()## we transform the input from 2D to 1Dself.flatten = nn.Flatten() elements = []# each layer is made of a linear layer with a ReLu activation and a DropOut Layerfor i inrange(len(hidden_dim)): elements.append( nn.Linear(input_dim, hidden_dim[i]) ) elements.append( nn.ReLU() ) elements.append( nn.Dropout(dropout_fraction) ) ## add regulation input_dim = hidden_dim[i] ## update the input dimension for the next layer elements.append( nn.Linear(input_dim, output_dim) )self.layers = nn.Sequential( *elements )def forward(self, x): x =self.flatten(x)## NB: here, the output of the last layer are logits logits =self.layers(x)return logits# initialize modelmodel = ProteinLoc_FNN(input_dim=8000, hidden_dim=[80], output_dim=10, dropout_fraction=0.25).to(device)print(model)## check modelprint(pms.summary(model, torch.zeros(1,400,20).to(device), show_input=True))
def train(dataloader, model, loss_fn, optimizer, echo=True, echo_batch=False): size =len(dataloader.dataset) # how many batches do we have model.train() # Sets the module in training mode.for batch, (X, y) inenumerate(dataloader): # for each batch X, y = X.to(device), y.to(device) # send the data to the GPU or whatever device you use for training# Compute prediction error pred = model(X) # prediction for the model -> forward pass loss = loss_fn(pred, y) # loss function from these prediction# Backpropagation loss.backward() # backward propagation # https://ml-cheatsheet.readthedocs.io/en/latest/backpropagation.html# https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html optimizer.step() optimizer.zero_grad() # reset the gradients# https://stackoverflow.com/questions/48001598/why-do-we-need-to-call-zero-grad-in-pytorchif echo_batch: current = (batch +1) *len(X)print(f"Train loss: {loss.item():>7f} [{current:>5d}/{size:>5d}]")if echo: current = (batch +1) *len(X)print(f"Train loss: {loss.item():>7f}")# return the last batch lossreturn loss.item()def valid(dataloader, model, loss_fn, echo =True): size =len(dataloader.dataset) num_batches =len(dataloader) model.eval() # Sets the module in evaluation mode valid_loss =0with torch.no_grad(): ## disables tracking of gradient: prevent accidental training + speeds up computationfor X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) valid_loss += loss_fn(pred, y).item() ## accumulating the loss function over the batches valid_loss /= num_batchesif echo:print(f"\tValid loss: {valid_loss:>8f}")return valid_loss
Utility functions
## get predicted and target from the modeldef get_model_predictions_and_y(model, dataloader): target = np.array([], dtype='float32') ## [] predicted = np.array([], dtype='float32') ## []with torch.no_grad():for X,y in dataloader: X = X.to(device) pred = model(X) target = np.concatenate([target, y.squeeze().numpy()]) ## extend -> concatenate for list predicted = np.concatenate([predicted, np.argmax(pred.to('cpu').detach().numpy() , axis=1) ] )return predicted, target## utility function: compute additional metrics during training besides entropy loss def get_additional_scores(predicted, target): return { 'balanced_accuracy': metrics.balanced_accuracy_score(target, predicted),'accuracy': metrics.accuracy_score(target, predicted),'f1': metrics.f1_score(target, predicted, average ='macro') }## format elapsed timedef format_time(seconds):if seconds <60:returnf"{seconds:.2f}s"elif seconds <3600: minutes =int(seconds //60) remaining_seconds = seconds %60returnf"{minutes}m {remaining_seconds:.2f}s ({seconds:.2f}s)"else: hours =int(seconds //3600) remaining_minutes =int((seconds %3600)) //60 remaining_seconds = seconds %60returnf"{hours}h {remaining_minutes}m and {remaining_seconds:.2f}s ({seconds:.2f}s)"
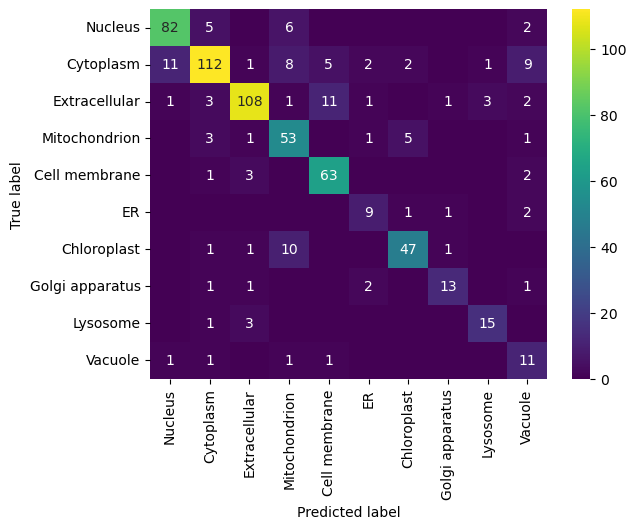
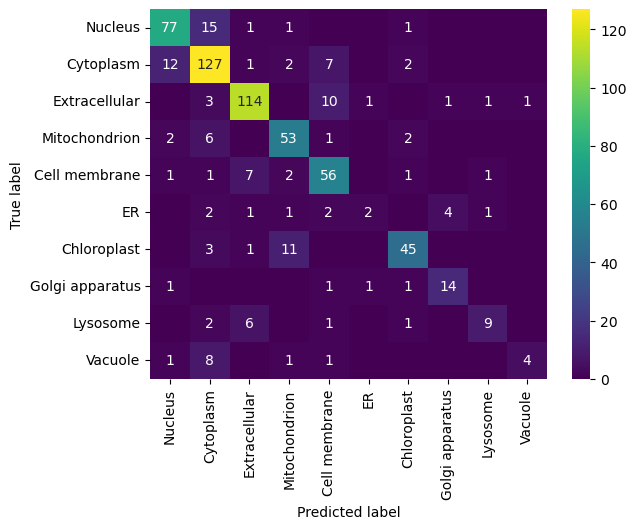
Plotting functions
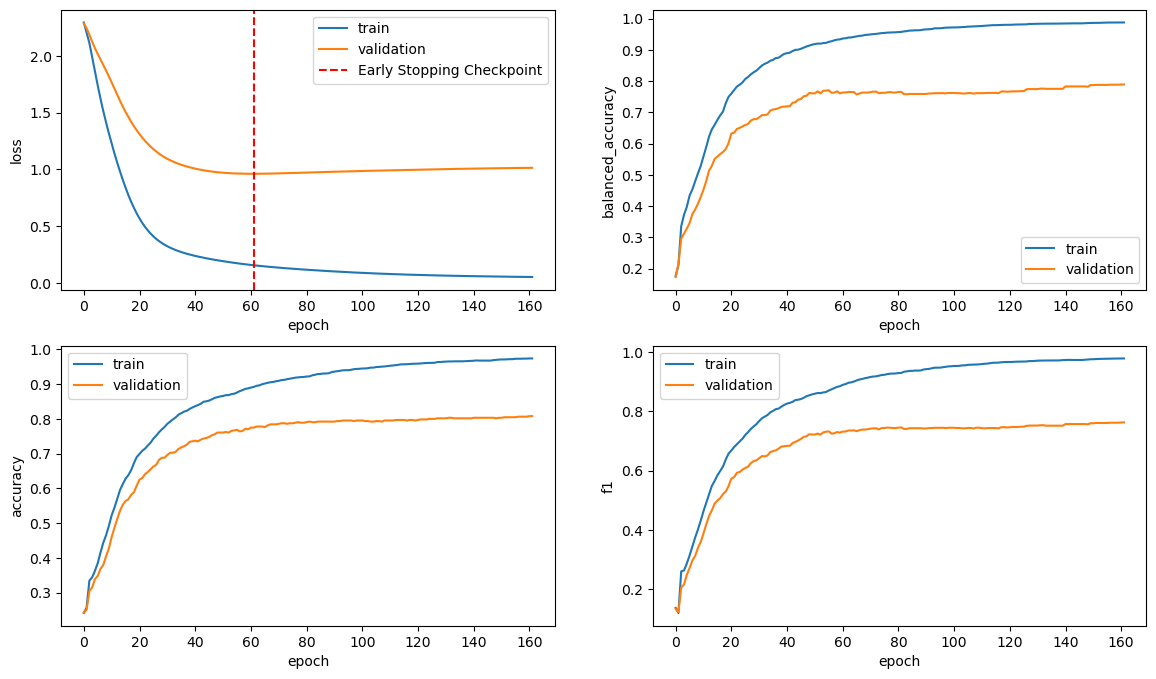
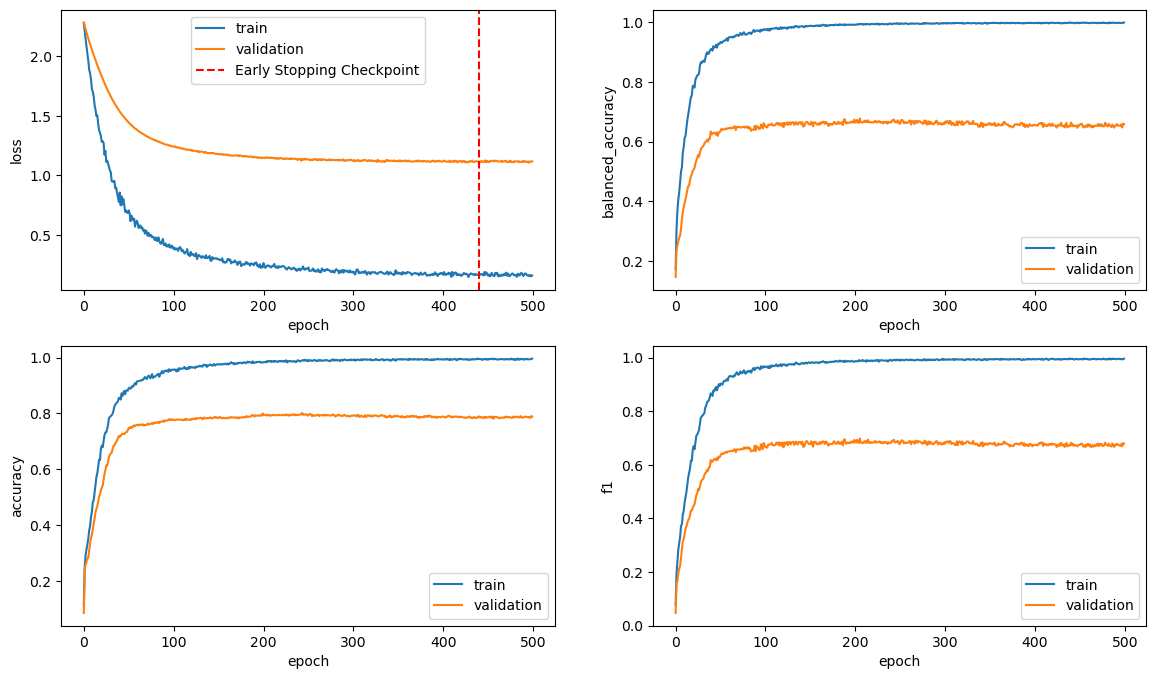
## plot training metricsdef plot_model_training(train_scores, valid_scores): fig, axes = plt.subplots(2,2,figsize = (14,8)) for i,k inenumerate( ['loss', 'balanced_accuracy', 'accuracy', 'f1'] ) : axes[i//2][i%2].plot(train_scores[k], label ='train') axes[i//2][i%2].plot(valid_scores[k], label ='validation')if k =='loss': axes[i//2][i%2].axvline(np.argmin(valid_scores[k]), linestyle='--', color='r',label='Early Stopping Checkpoint') axes[i//2][i%2].legend() axes[i//2][i%2].set_xlabel('epoch') axes[i//2][i%2].set_ylabel(k)## plot confusion matrixdef plot_confusion_matrix(model, X_valid_tensor, y_valid):## we can also use get_model_predictions_and_y() instead y_pred = model(X_valid_tensor.to(device)) y_pred = np.argmax(y_pred.detach().cpu().numpy(), axis=1) df = pd.crosstab(y_valid, y_pred, rownames=['truth'], colnames=['prediction']) df.columns = classes df.index = classes#trick to make the 0s dissapear sns.heatmap(df, annot = df.astype(str).replace('0',''), fmt ='s', cmap ='viridis') plt.ylabel('True label') plt.xlabel('Predicted label')## plotting accuracydef plot_accuracy(accuracy, xlabel, ylabel='Accuracy', title='Accuracy comparison'): plt.figure(figsize=(4,4)) acc_score = accuracy x = np.arange(len(acc_score)) plt.bar(x, acc_score) plt.title(title) plt.ylabel(ylabel) plt.xticks(x, xlabel, rotation=60)for i, v inenumerate(acc_score): plt.text(i, v-0.07, '%.3f'%v, color='white', fontweight='bold', ha='center')
def train_ProteinLoc(model = ProteinLoc_CNN().to(device), lr=10**-3, weight_decay=0, ## default Adam parameters setting epochs=100, patience=25):## set the model model = model## set the loss function counting class unbalancing n_class=10 W = torch.Tensor(compute_class_weight(class_weight='balanced', classes = np.array(list(range(n_class))), ## map subcell locations to int y= y_train)).to(device) CEloss = nn.CrossEntropyLoss(weight = W)#print('weights_classes',W.cpu().numpy())## set the optimizer: https://pytorch.org/docs/stable/generated/torch.optim.Adam.html optimizer = torch.optim.Adam(model.parameters(), lr = lr, weight_decay = weight_decay)## early stopping: prevent overfitting and reduce training time early_stopping = EarlyStopping(patience=patience, verbose=False)## keep the scores across epochs train_scores = {'loss':[], 'balanced_accuracy':[], 'accuracy':[], 'f1':[]} valid_scores = {'loss':[], 'balanced_accuracy':[], 'accuracy':[], 'f1':[]}## train the model across epochsfor t inrange(1,epochs+1): echo = t%10==0if echo:print('Epoch',t ) ## training set train_scores['loss'].append(train(train_dataloader, model, CEloss, optimizer, echo=echo, echo_batch=False)) pred_train, target_train = get_model_predictions_and_y(model, train_dataloader) train_metric = get_additional_scores(pred_train, target_train)## validation set valid_scores['loss'].append(valid(valid_dataloader, model, CEloss, echo=echo)) pred_valid, target_valid = get_model_predictions_and_y(model, valid_dataloader) valid_metric = get_additional_scores(pred_valid, target_valid)## add extra metricfor k in ['balanced_accuracy', 'accuracy', 'f1']: train_scores[k].append(train_metric[k]) valid_scores[k].append(valid_metric[k]) early_stopping(valid_scores['loss'][-1], model) ## send last valid_score to early stopif early_stopping.early_stop:print("Early stopping")breakprint("Done!")return train_scores, valid_scores, model, CEloss, optimizer
Hyperparmeters
Hyperparmeters configuration used for training/testing all the models - for a fair comparison
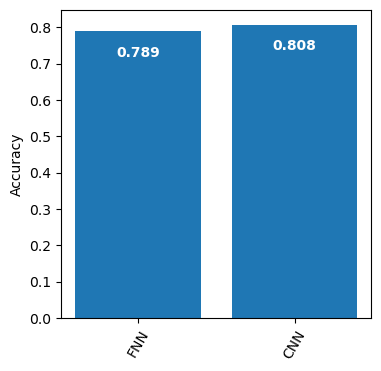
## other way of computing accuracy# from sklearn.metrics import confusion_matrix# cm_fnn = confusion_matrix(y_valid, y_pred_fnn)# accuracy_fnn = np.trace(cm_fnn) / np.sum(cm_fnn)accuracy_cnn = get_additional_scores(y_pred_cnn, y_cnn)['accuracy']accuracy_fnn = get_additional_scores(y_pred_fnn, y_fnn)['accuracy']## plot accuracy plot_accuracy(accuracy=[accuracy_fnn, accuracy_cnn], xlabel=['FNN','CNN'], ylabel='Accuracy', title='')
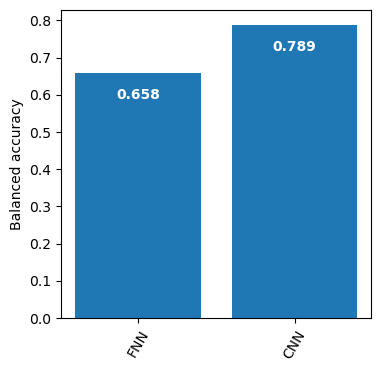
Balanced accuracy comparison
## compute balanced accuracy over subcellular localizations (classes)balanced_accuracy_cnn = get_additional_scores(y_pred_cnn, y_cnn)['balanced_accuracy']balanced_accuracy_fnn = get_additional_scores(y_pred_fnn, y_fnn)['balanced_accuracy']## plot accuracy## note: p -> padding and s -> stride plot_accuracy(accuracy=[balanced_accuracy_fnn, balanced_accuracy_cnn], xlabel=['FNN','CNN'], ylabel='Balanced accuracy', title='')
Conclusions and considerations
CNN slightly outperforms FNN, but at a much higher computational cost: CNN took 12min while FNN took 10sec in current configuration
Increasing the number of output channels (i.e. feature maps) boosts CNN performance, but at the cost of increased training time. For instance, a CNN with 80 output channels yielded an accuracy of around 0.82 after roughly 40 minutes of training (data not shown).